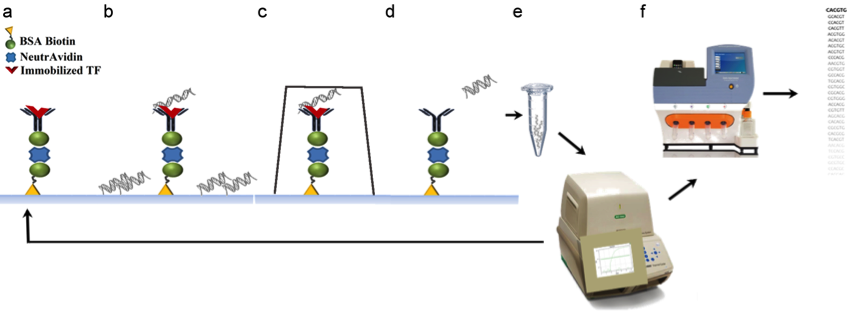
SELMAP technology was developed by Rada Golodintsky, Dana Chen and Dorit Avrahami in Doron Gerber's lab at Bar-Ilan University.
The software to analyze the data was developed by Yaron Orenstein in Ron Shamir's Computational Genomics group at Tel Aviv University.
The file contains all the sequencing files produced and analyzed in the study in fastq.gz format.
The file contains the processed data in a form of 6-mer scores and PWM files.
Java executable distribution (SELEX.jar)
Java executable distribution (SELEX-est.jar)
This distribution is our officially supported executable for SELMAP. This binary is completely self-contained and should work out of the box without any issues.
The software is freely available under the GNU Lesser General Public License, version 3, or any later version at your choice.
SELMAP is a research tool, still in the development stage. Hence, it is not presented as error-free, accurate, complete, useful, suitable for any specific application or free from any infringement of any rights. The Software is licensed AS IS, entirely at the user's own risk.
java -jar SELEX.jar <k> <barcode> <length> <output_file> <output_file_RC> <output_file_pwms> <seed> <cycle_0_file> <cycle_1_file> ...
SELEX-est receives the same arguments, and computes an additional k-mer ratio score, based on estimated frequencies in intial round.
Example run:
java -jar SELEX.jar 6 TAGCTC 18 Pho4_Full_6mers.txt Pho4_Full_6mers_RC.txt Pho4_Full_pwm.txt CACGTG Library1_Cycle0_barcode_TAGCTC.fastq Pho4_Cycle1_Full_Chip_lib1.fastq Pho4_Cycle2_Full_Chip_lib1.fastq Pho4_Cycle3_Full_Chip_lib1.fastq
java -jar SELEX.jar 6 TAGCTC 18 Pho4_Library1_6mers.txt Pho4_Library1_6mers_RC.txt Pho4_Library1_pwm.txt CACGTG Library1_Cycle0_barcode_TAGCTC.fastq Pho4_2libraries_cycle2.fastq
java -jar SELEX.jar 6 ACTGAA 18 Pho4_Library2_6mers.txt Pho4_Library2_6mers_RC.txt Pho4_Library2_pwm.txt CACGTG Library2_Cycle0_barcode_ACTGAA.fastq Pho4_2libraries_cycle2.fastq
java -jar SELEX.jar 6 TAGCTC 18 atERF2_Library1_6mers.txt atERF2_Library1_6mers_RC.txt atERF2_Library1_pwm.txt GCCGCC Library1_Cycle0_barcode_TAGCTC.fastq atERF2_2libraries_cycle2.fastq
java -jar SELEX.jar 6 ACTGAA 18 atERF2_Library2_6mers.txt atERF2_Library2_6mers_RC.txt atERF2_Library2_pwm.txt GCCGCC Library2_Cycle0_barcode_ACTGAA.fastq atERF2_2libraries_cycle2.fastq atERF2_2libraries_cycle3.fastq
java -Xmx4096m -jar SELEX-est.jar 10 TAGCTC 18 BTD_results_10mers.txt BTD_results_10mers_rc.txt BTD_results_10mers_pwm.txt CGGGCGCGCC Library1_Cycle0_barcode_TAGCTC.fastq BTD-rnd-1_S15_L001_001.fastq.18 BTD-rnd-2_S16_L001_001.fastq.18 BTD-rnd-3_S17_L001_001.fastq.18
java -Xmx4096m -jar SELEX-est.jar 10 TAGCTC 18 Pho4_Full_10mers.txt Pho4_Full_10mers_RC.txt Pho4_Full_10pwm.txt CCCACGTGGG Library1_Cycle0_barcode_TAGCTC.fastq Pho4_Cycle1_Full_Chip_lib1.fastq Pho4_Cycle2_Full_Chip_lib1.fastq Pho4_Cycle3_Full_Chip_lib1.fastq
java -Xmx4096m -jar SELEX-est.jar 10 ACTGAA 18 atERF2_Library2_10mers.txt atERF2_Library2_10mers_RC.txt atERF2_Library2_10pwm.txt CTGCGCCGCC Library2_Cycle0_barcode_ACTGAA.fastq atERF2_2libraries_cycle2.fastq atERF2_2libraries_cycle3.fastq
Kmer Count_0 Freq_0 Count_1 Freq_1 Ratio_1 Ratio_0 Count_2 Freq_2 Ratio_2 Ratio_0 Count_3 Freq_3 Ratio_3 Ratio_0 AAAAAA 342 1.4E-4 208 1.3E-4 0.928 0.928 235 1.2E-4 0.918 0.851 90 3.3E-5 0.264 0.225 CAAAAA 380 1.6E-4 218 1.4E-4 0.875 0.875 271 1.4E-4 1.010 0.884 184 6.8E-5 0.469 0.415 GAAAAA 434 1.8E-4 237 1.5E-4 0.833 0.833 294 1.5E-4 1.008 0.839 136 5.0E-5 0.320 0.268 TAAAAA 452 1.9E-4 277 1.8E-4 0.935 0.935 301 1.6E-4 0.882 0.825 128 4.7E-5 0.294 0.242 ACAAAA 399 1.7E-4 273 1.8E-4 1.044 1.044 302 1.6E-4 0.898 0.938 233 8.6E-5 0.533 0.500 ...Each line starts with a k-mer string, correpsonding to a unique k-mer.
The PWM output should look like this:
A: 0.183147132396698 0.22810086607933044 0.11032721400260925 0.8135622143745422 0.9158732891082764 . . . C: 0.2849732041358948 0.14351284503936768 0.32613304257392883 0.028032639995217323 0.017520010471343994 . . . G: 0.26065367460250854 0.10847616195678711 0.21236343681812286 0.11921338737010956 0.04402954876422882 . . . T: 0.2712264955043793 0.5199114084243774 0.35117655992507935 0.03919265791773796 0.022574998438358307 . . .Each line is of the form
nucleotide: [tab] probability_pos_1 [tab] probability_pos_2 [tab] . . .
SELMAP - SELEX Affinity Landscape Mapping of transcription factor binding sites using integrated microfluidics
Dana Chen*, Yaron Orenstein*, Rada Golodintsky, Chaim Wachtel, Michal Pellach, Dorit Avrahami, Avital Ovadia-Shochat, Hila Shir-Shapira, Adi Kedmi, Tamat Juven-Gershon, Ron Shamir and Doron Gerber.
* Authors contributed equally to the work.
Scientific Reports (2016).